
データ分析を実施しようと思ったとき、分析に使いたいデータが別々のエクセルファイルやデータシートに分かれて保存されていることが多々あります。そんなとき、Pandasのmergeメソッドが便利です。mergeメソッドを使えば、共通のキー(列データ)を基にしてデータを結合(統合)することができます。今回の記事では、mergeメソッドについて解説をします。
今回の記事も公式のドキュメントを参考に初心者でも分かりやすいよう解説しています。興味があれば公式ドキュメントも御覧ください。
mergeメソッドの基本的な機能
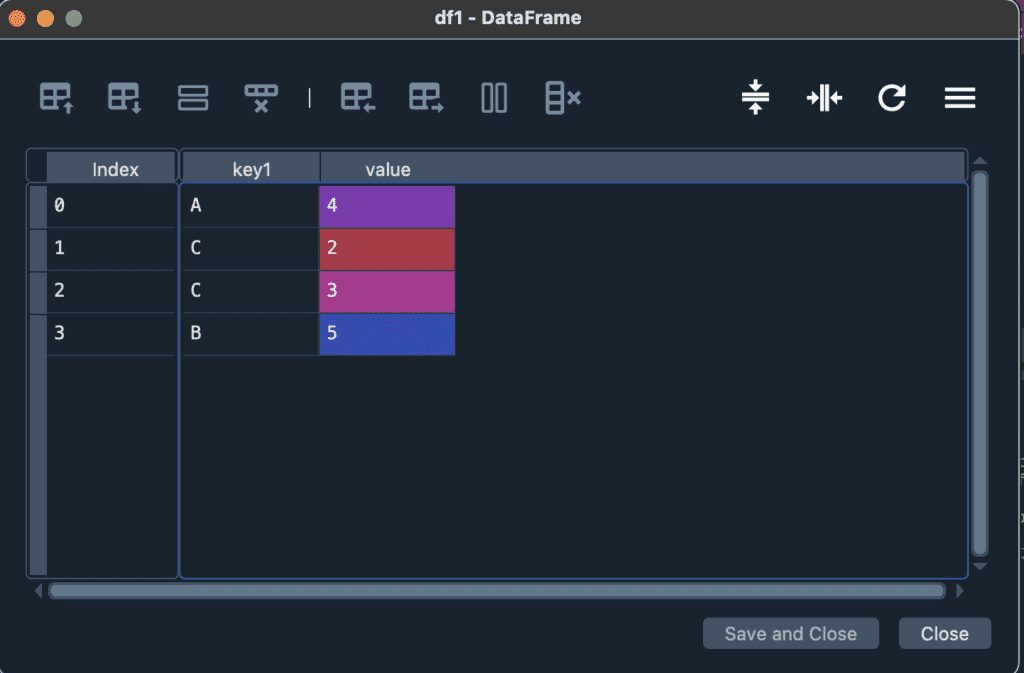
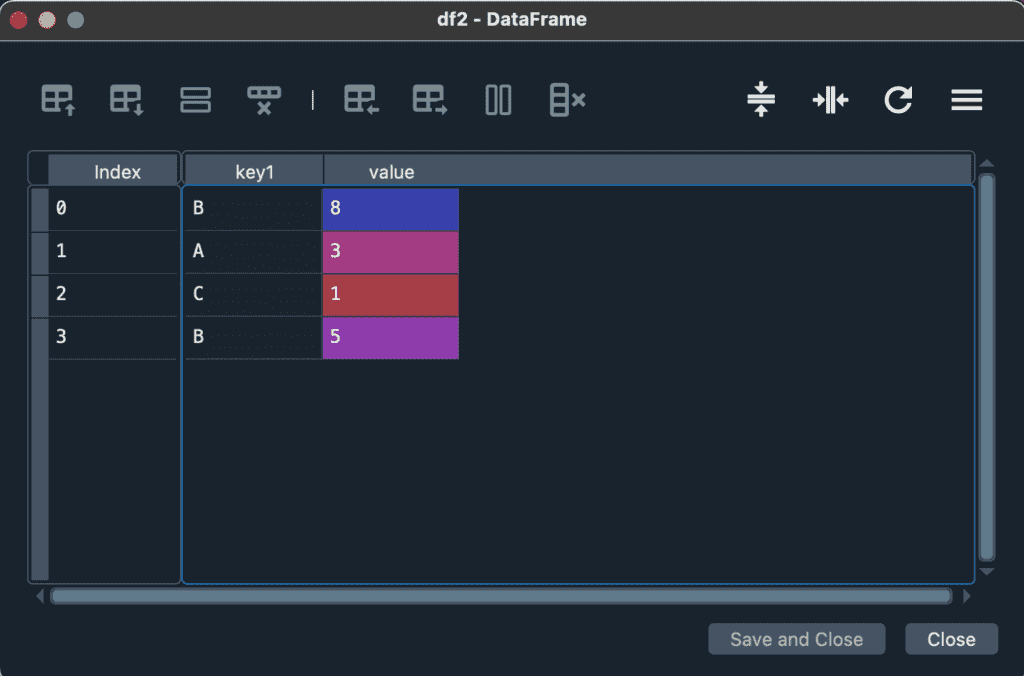
mergeは、データ同士を結合するメソッドになります。基本的には、2つのデータの共通の列をキーにして、キー列に共通するデータ(キーデータ)があれば、キーデータを含む行同士を結合します。最も単純な例として、共通の列を2つ持つdf1とdf2を、mergeを使って結合し、df3を生成する場合を紹介します。
import pandas as pd
# 共通のキーを持つデータフレームを作成
df1 = pd.DataFrame({'key1': ['A', 'C', 'C', 'B'],
'value': [4, 2, 3, 5]})
df2 = pd.DataFrame({'key1': ['B', 'A', 'C', 'B'],
'value': [8, 3, 1, 5]})
# mergeを使ってdf1とdf2を結合したdf3を作成
df3 = df1.merge(df2)実行すると、df1とdf2の2つのデータフレームで、共通のデータを持った部分だけ残った、df3が生成されました。
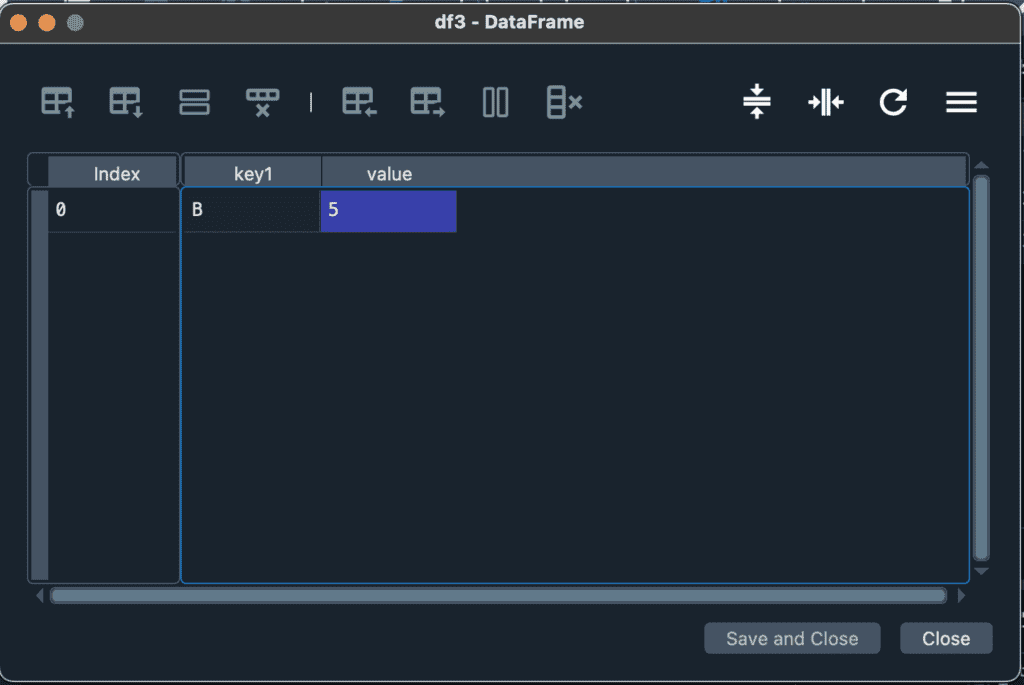
少し違った例として、df1のvalueの列名だけ、value1に変更した例を挙げます。こちらでは、共通するkey列のみ統合され、valueとvalue1はいずれも残ります。ここで面白いのは、df3のデータが元になったdf1とdf2よりも増えている点です。これは、df1のkey1列に含まれるBというデータに対応するdf2のデータが2つあるためです。
import pandas as pd
# 共通のキーを持つデータフレームを作成
df1 = pd.DataFrame({'key1': ['A', 'C', 'C', 'B'],
'value1': [4, 2, 3, 5]})
df2 = pd.DataFrame({'key1': ['B', 'A', 'C', 'B'],
'value': [8, 3, 1, 5]})
# mergeを使ってdf1とdf2を結合したdf3を作成
df3 = df1.merge(df2)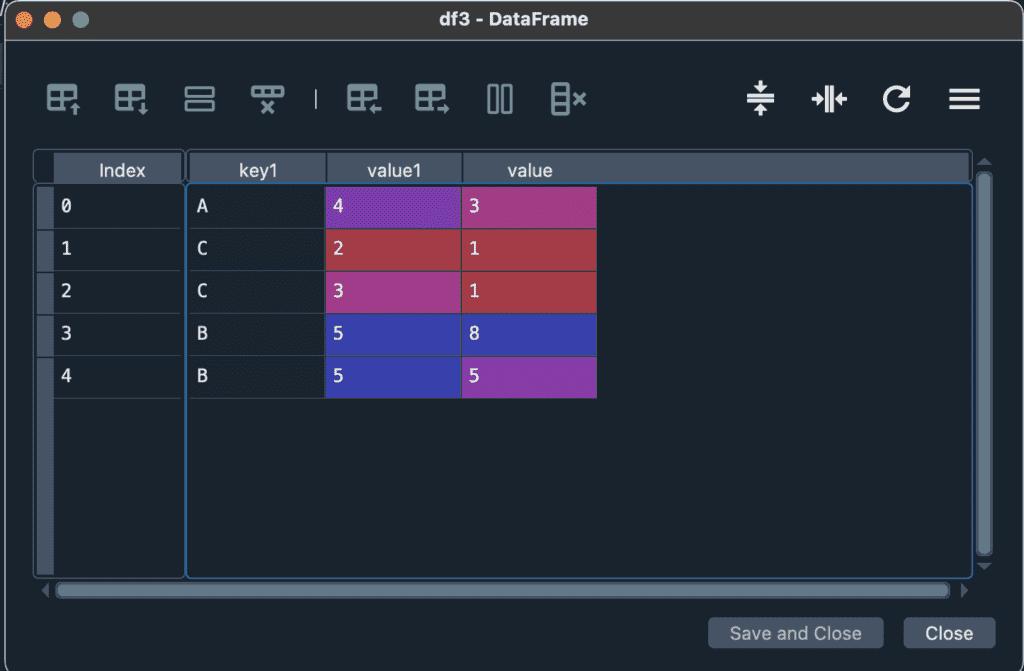
mergeメソッドの主要パラメーター
基本的な機能を解説したところで、今度はmergeメソッドの様々な機能(パラメーター)について紹介します。今回はよく使う、howとon、suffixesについて解説します。他のパラメーターについては公式のドキュメントを御覧ください。
howパラメーター
howはデフォルトで”inner”が指定されています。innerの場合、キーが完全一致する場合に限りデータが残りますが、例えば”outer”を指定すると、キーのどれかが一致すれば、データが残ります。論理式の”かつ”がinner、”または”がouterだと思えば良いです。下にhow = outerで指定した場合のコードと出力結果を示します。
import pandas as pd
# 共通のキーを持つデータフレームを作成
df1 = pd.DataFrame({'key1': ['A', 'C', 'C', 'B'],
'value': [4, 2, 3, 5]})
df2 = pd.DataFrame({'key1': ['B', 'A', 'C', 'B'],
'value': [8, 3, 1, 5]})
# mergeを使ってdf1とdf2を結合したdf3を作成
df3 = df1.merge(df2, how = "outer")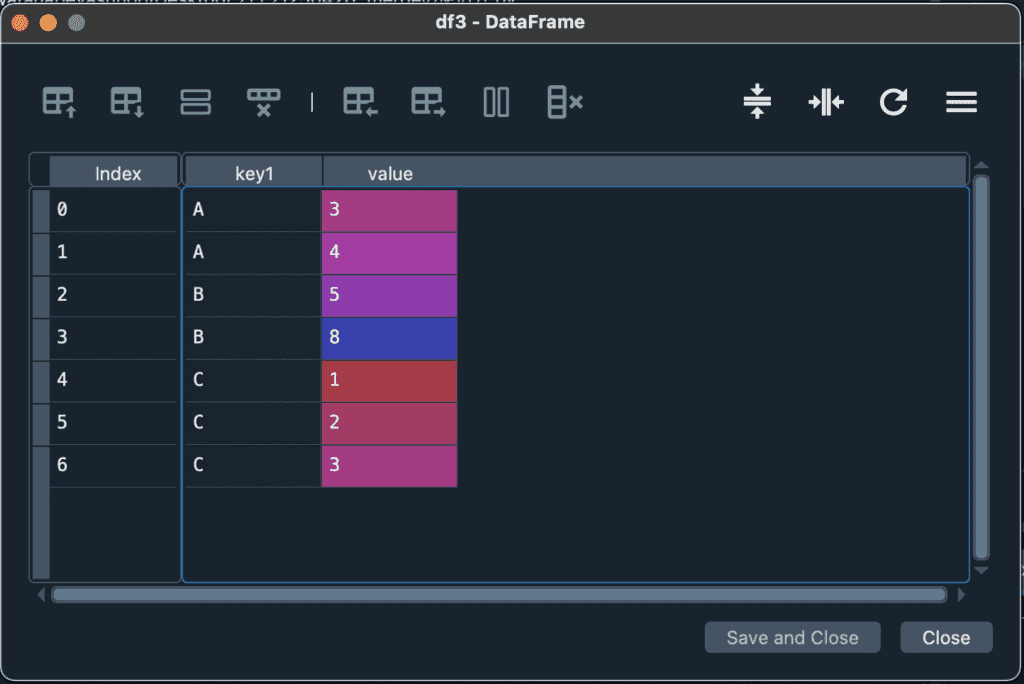
onパラメーター
デフォルトは、共通する列名があれば、全てキー列になります。onパラメーターは、データを結合する際に使うキー列の指定に使います。翻ると、onで指定した列以外は、仮に同じ列名だとしても、別々の列として認識されます。例えば、on = “key1″を指定した場合を紹介します。
import pandas as pd
# 共通のキーを持つデータフレームを作成
df1 = pd.DataFrame({'key1': ['A', 'C', 'C', 'B'],
'value': [4, 2, 3, 5]})
df2 = pd.DataFrame({'key1': ['B', 'A', 'C', 'B'],
'value': [8, 3, 1, 5]})
# mergeを使ってdf1とdf2を結合したdf3を作成
df3 = df1.merge(df2,on="key1")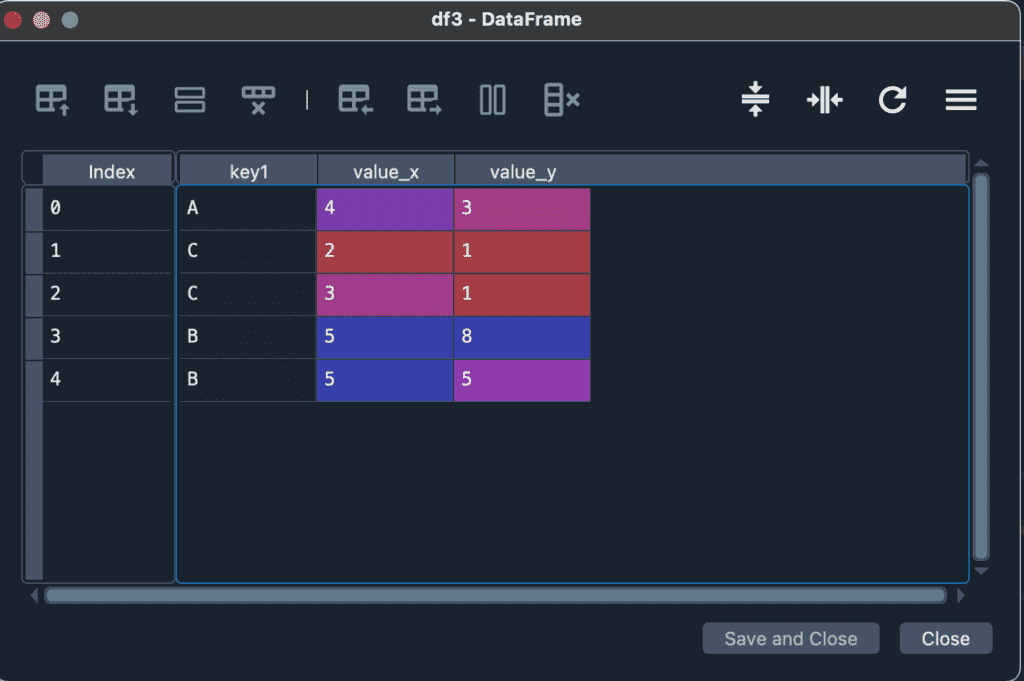
df1とdf2は”value”が共通の列名で存在していましたが、今回は別々の列として認識されました。同じ列名のデータが合った場合、デフォルトで”_x”と”_y”が付けられ、自動で列名が変わります。
suffixesパラメーター
suffixパラメーターは、共通の列名があったときに末尾が”_x”や”_y”などに変わるところを変更できます。”_x”と”_y”に代わり、”_df1″と”_df2″に変更した例を示します。
import pandas as pd
# 共通のキーを持つデータフレームを作成
df1 = pd.DataFrame({'key1': ['A', 'C', 'C', 'B'],
'value': [4, 2, 3, 5]})
df2 = pd.DataFrame({'key1': ['B', 'A', 'C', 'B'],
'value': [8, 3, 1, 5]})
# mergeを使ってdf1とdf2を結合したdf3を作成
df3 = df1.merge(df2,on="key1", suffixes=("_df1", "_df2"))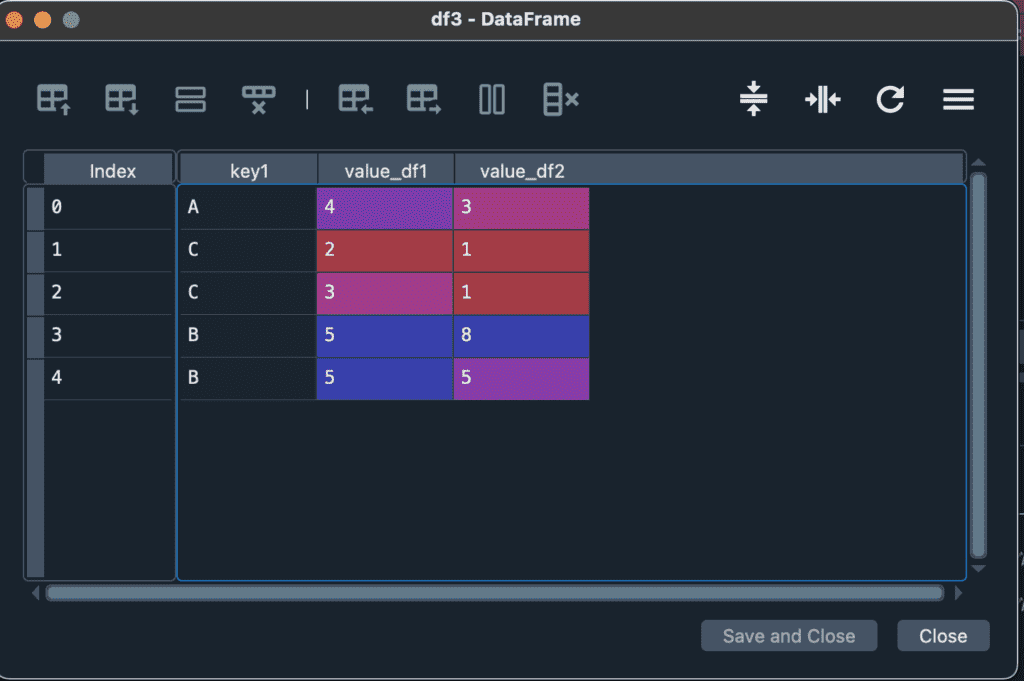
まとめ
以上、pandasのmergeメソッドについて紹介しました。複数のデータを共通のキーを使って結合するときに非常に強力なメソッドになります。一方で、どのように結合されるのか理解せずに使用すると、必要なデータ消えてしまったり、余計なデータが複製されて、正確な分析に寄与できなくなります。
もしなにか解説を希望するものがあれば、ぜひコメント下さい!


コメント