前回の記事ではデータの整形をメインに解説を行いました。本記事では、整形したデータを実際に分析するための実践的な方法について解説をします。
はじめに何を確認するか?確認すべき項目とは?
データを整形したあとにはじめに実施すべき分析は、以下の2点です。
- (各項目の)相関の確認
- 散布図の描画
基本的には、1をやったあと2を行うことが多いと思います。1については、網羅的に全ての項目を確認する場合より、注目している特性に対する各項目の相関を見に行くケースが主です。今回の記事では網羅的に相関を確認する方法と、注目している項目のみの相関を確認する方法をそれぞれ紹介しようと思います。
相関を確認したあとは、散布図を描画します。基本として、相関の確認と散布図の描画はセットです。その理由は【散布図の描画】の項目で解説します。
相関の確認
今回扱うデータ(dfとします。)は、A, B, C, Dの4つの項目(カラム名)について、それぞれ30個の値を持つとします。まずは全ての項目間の相関を確認するため、以下のコードを実行します。
corr_matrix = df.corr(numeric_only = True)相関の確認は、pandasのcorrメソッドを使って実施します。corrメソッドを実行することで、各項目間の相関を一覧化した、相関行列を得られます。今回、相関行列はcorr_matrixという名前(変数名)で扱うこととしています。()内のnumeric_only =Trueは、数値データだけ相関の計算を行うという指示です。データの中に数値データ以外が入っている場合は必須となります。
個別の項目の相関を確認する際は、corr_matrixからデータを抜き出します。例えば、Aカラムに着目する際は、以下のコードを実行します。corr_matrixもデータフレームなので、通常のデータフレーム形式と同じように列名を指定することでデータを取得出来ます。
df_corrA = corr_matrix["A"]散布図の描画
相関を確認したあとは、データを散布図で描画します。今回は、AとCの相関が強かったため、x軸をC、y軸をAとして描画します。描画するためのモジュールは複数ありますが、今回はmatplotlibを使って描画します。まずは、matplotlibをimportします。
import matplotlib.pyplot as pltmatplotlibをimportしたら、描画のため以下のコードを実行します。
plt.scatter(df["C"], df["A"])
plt.show()散布図はmatplotlibのscatterメソッドを使います。()内で、まずはx軸となるdf[“C”](データフレームdfのC列を指定するため、このような書き方になります)を、次にy軸となるdf[“A”]を指定します。最後に、plt.show()で作成したグラフを表示します。
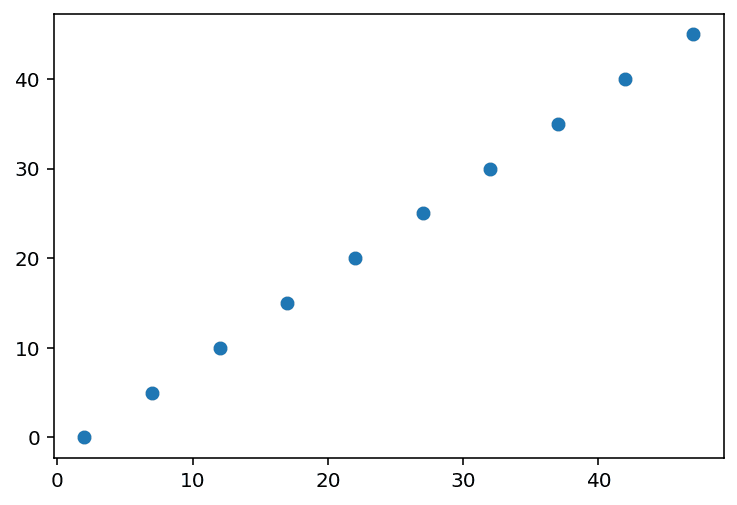
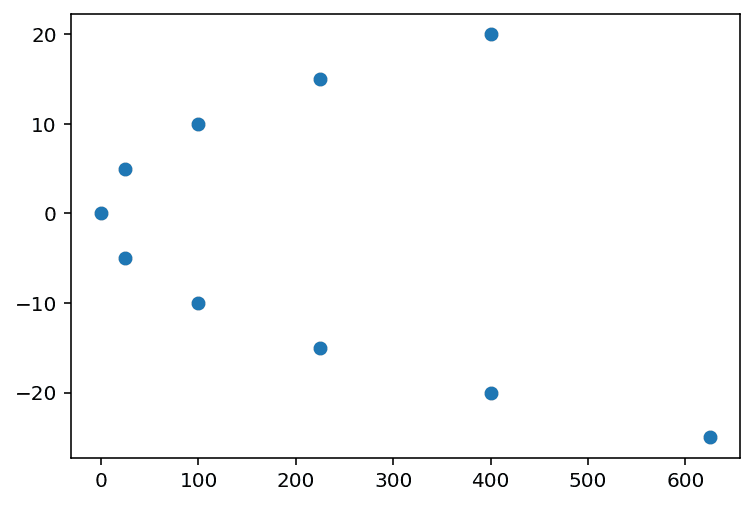
相関と散布図の作成はセットと言う話に戻りますが、これは相関に騙されないためです。相関係数が低くとも、実は規則的なプロット(例えば2次関数の関係とか。下図を参照。)になっているケースもあります。相関係数は、あくまで項目間の1次の関係性だけを見ているため、より高次の関係性については何も語ってくれません。
まとめ
今回は、データ分析の初歩である相関の確認と散布図の描画に関する初歩を記事にしました。今後の記事では、散布図以外の描画やグラフのカスタム方法について解説したいと思います。


コメント